 迁址公告
迁址公告
 古东管家APP
古东管家APP
 关于我们
关于我们
十年后,当我们回看过去,2026年5月3日一定是具有标志性意义的一天:
欧盟《人工智能法案》(正式版)和中国的《AI伦理审查办法》在同一天相继发布。
两大经济体好似隔空打了个配合,给狂野生长的AI行业套上同款“紧身衣”。
像,实在是太像了。
01
两大法案的监管逻辑,在三个方向上高度一致。
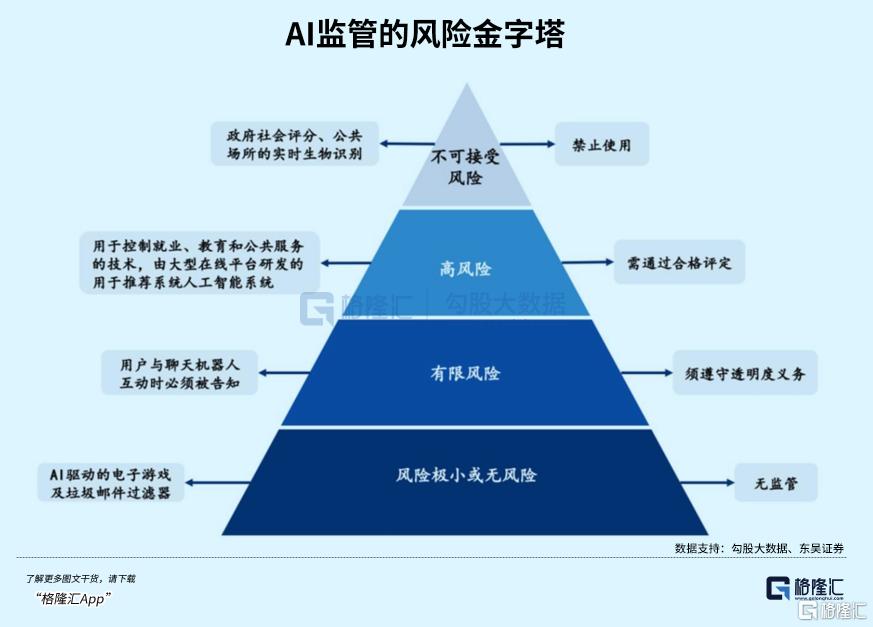
1.禁止类边界
不允许AI给人打分,尤其在征信、道德方面,以此决定你能不能贷款、能不能坐高铁。
类似《黑镜》里因为评分低就被社会边缘化的可能性,要从苗头上就扼杀。
不允许深度伪造滥用。
比如2024年美国大选期间,新罕布什尔州选民接到拜登AI合成的语音电话,劝他们不要去投票的。
当时是没有监管,现在,用AI换脸、伪造声音去诈骗、搞政治操纵或者毁人清白,属于一级重罪。
不允许虚假信息生成,制造假新闻洗脑大众。

2.高风险场景要求
简单来说,AI必须说“人话”,必须有“监护人”。
尤其在医疗、教育、司法三大领域,提出了极为苛刻的要求:强制可解释性和人类监督。
什么叫强制可解释性?
深度学习神经网络是典型“黑盒子”。
比如在医疗诊断中,AI说病人得了肺癌,医生问为什么,它只会甩出一堆参数。
以后这是绝对不允许的。
AI必须能用人类听得懂的逻辑说出,它看到了什么、符合什么特征、所以给出这个诊断。
人类监督好理解,AI无论是判案、做手术、批改试卷,最后敲下回车键的,必须是活生生的人类。
它只有执行权,没有决定权。
3.大模型透明度
第一,训练数据版权溯源。
过去几年,大量创业者都是在互联网上无差别爬取数据,几乎是纯白嫖来训练模型。
以后不行了,必须交代清楚数据是哪来的,有没有授权。
第二,安全评估报告。
模型上线前必须强制进行“红蓝对抗测试”,出具详尽的安全性评估报告。
怎么才叫安全?
比如,你自己雇一群黑客,想方设法地诱导你的AI说出制造炸弹的配方,但它就是不说,以此来证明其安全底线。
只有这样,它才能进入市场。
以上这些规定,一旦违反,惩罚极其严重。
《AI法案》明文规定,违反“禁止类AI实践”,最高将面临3500万欧元或公司上一财年全球总营业额7%的罚款,两者取其高。
相比之下,最严厉的隐私法GDPR,最高罚款也“才”全球营收的4%。
中国这边,看似语气比欧盟柔和,实则本土化管控穿透力更强。
明文禁止人格分级社会评分、无授权深度伪造人脸/语音、全自动舆情虚假生成模型,机构违规最高罚款1000万元,个人责任人最高处罚50万元,并处行业禁入。
医疗辅助诊断、校园智能考评、司法智能研判三类AI产品,上市前必须完成伦理备案,否则责令停产整改,扣除全部行业补贴,且6个月内禁止申报任何AI科创项目。
国内大模型企业完成训练数据集合规标注,标注覆盖率不得低于92%,开源模型需公开数据来源清单。
2026年Q4起,未完成版权溯源的模型,禁止商业化迭代升级。
相比于罚钱,暂停API服务、下架APP、甚至吊销算法备案号,明显更让人胆寒。
如此严格,AI技术的发展,是否会因此放缓?
02
答案是不会。
但会强制改道。
根据Gartner发布的《新兴技术技术成熟度曲线》的看法,生成式AI实际上早就越过了“期望膨胀期”,正在向注重实际投资回报率的阶段演进。
当技术脱去了炒作的外衣,企业关注的焦点必然从“它有多神奇、多强大”转向“它有多安全、多合规”。
而这些,必须要强监管才能实现。
在此背景下,AI的研发重心已然转向。
1.从单纯注重规模,到更注重RAG(检索增强生成)
之前,所有厂商都在比谁的参数大,谁的模型能把全世界的知识都背下来。但这带来了严重的“幻觉”问题,且极其不透明。
以后,“大力出奇迹”虽然依然重要,但只会是少数巨头的游戏,RAG技术才是企业级AI的标配。
RAG的逻辑是:AI你别瞎编,你先去我指定的、合规的、经过版权清理的企业内部数据库里把资料找出来,然后再根据这些资料进行总结。
这样一来,AI说的每一句话都能给出具体的文档出处,契合《法案》对透明度和可解释性的要求。
2.对齐与安全
做个拟人化的比喻,之前给AI做“基于人类反馈的强化学习”,就像是给它请了个遵循人类礼仪人类老师,并没有改变它本质上的逻辑。
在严格的安全评估报告要求下,AI需要的不再是“老师”,而是必须遵守的法律。
Anthropic首创的Constitutional AI(宪法AI)理念必然被广泛引用,大模型在设计之初,就必须把不作恶、不歧视等原则硬编码到损失函数中。
3.隐私计算崛起
既然不让随便爬数据,又要保护高风险场景的用户隐私,怎么办?
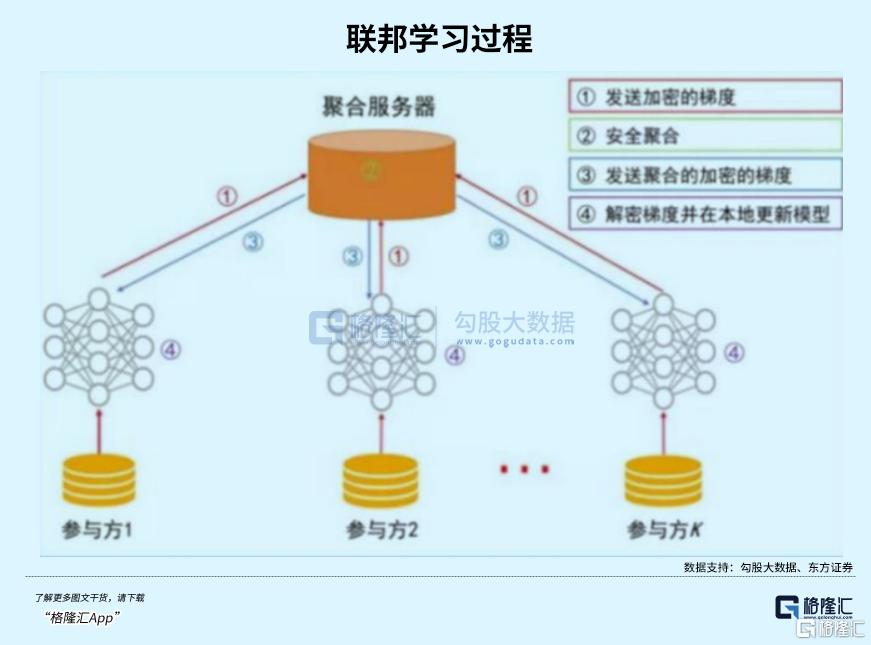
联邦学习和差分隐私技术必然成为刚需。
比如,几家医院想联合训练医疗AI,但又不能共享病人的敏感数据。
此时,联邦学习就能做到“数据可用不可见”,让模型在各家医院的服务器上分别训练,最后只共享模型参数,不共享原始数据。
这类合规技术将成为VC们下一个疯抢的香饽饽。
换句话说,整个行业的格局将很快发生变化。
先说受益者。
最大的受益者,还是目前活跃的大厂。
有个词叫“监管俘获”。
合规是有极高成本的。要搞数据版权溯源、养几百人的安全评估团队……这些硬性门槛,可以说本身就把绝大多数想做大模型底座的草根创业公司挡在了门外。
巨头们凭借深厚的资金池和法务团队,轻松跨过门槛,合规反而成了他们最宽广的护城河。
所以,监管法案看起来是在限制巨头,但它们凭借深厚的资金池和法务团队,可以轻松跨过门槛,合规反而成了他们最宽的护城河。
其次是To B企业服务软件巨头与合规工具开发商。
根据麦肯锡发布的《生成式AI的经济潜力》报告测算,生成式AI每年有潜力为全球经济贡献2.6万亿至4.4万亿美元的价值。
这块大蛋糕不会因为监管而消失,而是加速向B端转移。
企业客户最怕的是什么?是违规、是罚款、是声誉受损。
因此,能提供“开箱即用、完全合规、带解释性”的AI企业服务公司,以及专门做AI水印、深伪检测、合规审计的SaaS公司,大概率将迎来业绩的爆炸式增长。
再看受损者。
“套壳”创业公司首当其冲。
这几年,市面上涌现了成千上万家只靠调用大厂API,套个UI界面就敢出来骗融资的公司。
现在法案要求高风险场景必须有可解释性和透明度,这些套壳公司根本接触不到底层的模型参数,也拿不出数据来源证明。
当客户向他们索要安全评估报告时,他们必然拿不出来,最终的结局就是批量倒闭。
然后是野蛮生长的开源社区。
法案对于“透明度”的要求是一视同仁的。
你开源一个大模型,如果被别人拿去搞诈骗,或者你的训练数据里包含了大量未授权的版权内容,开源作者要不要承担连带责任?
虽然法案对纯科研用途有一定的豁免,但在商业化边缘疯狂试探的开源项目,将面临巨大的法律阻击。
开源模型的发布将变得更加谨慎,以往那种“随便扔到GitHub上就不管了”的狂野时代将一去不复返。
03
看到这里,我们可以得出一个结论:
强监管的落地,并非AI创新的终结,而是新技术真正“大规模商业化变现”的开始。
市场最厌恶的就是不确定性。
在监管落地之前,企业对AI应用可以说是既眼馋又害怕,生怕哪天踩了红线惹上官司。
现在规矩定好了,高压线划清楚了,企业反而能放开手脚,在合规的框架内砸预算去采购AI服务。
所以还是那句话,AI技术的发展并不会因此放缓,只会在To B市场迎来更深沉、更稳健的爆发。
只有让AI戴上脚镣、真正学会遵守规矩,它才能安全地走进每个人的生活。
免责声明:所有平台仅提供服务对接功能,资讯信息、数据资料来源于第三方,其中发布的文章、视频、数据仅代表内容发布者个人的观点,并不代表泡财经平台的观点,不构成任何投资建议,仅供参考,用户需独立做出投资决策,自行承担因信赖或使用第三方信息而导致的任何损失。投资有风险,入市需谨慎。
请先登录后发表评论